Abstract
As virtual cities become ever more common and more extensive, the need to populate them with virtual pedestrians grows. One of the problems to be resolved for the virtual population is the behaviour simulation. Currently specifying the behaviour requires a lot of laborious work. We propose a method for automatically deriving the high level behaviour of the avatars. We introduce to the Graphics community a new method adapted from ideas recently presented in the Architecture literature. In this method, the general avatar movements are derived from an analysis of the structure of the architectural model. The analysis tries to encode Gibson's principle of affordance, interpreted here as: pedestrians are more attracted towards directions with greater available walkable surface. We have implemented and tested the idea in a 2x2 km2, model of the city of Nicosia. Initial results indicate that the method, although simple, can automatically and efficiently populate the model with realistic results.
Introduction
The behaviour simulation of the avatars can be separated into high-level behaviour, involved mainly with what the avatars want to do and what direction they want to follow; and the more low level processes such as path planning or interaction with other avatars. In this paper we will mainly be concerned with the high level decisions. We have implemented a complete system with 3D avatar rendering, collision avoidance and a very effective path following method to allow us to test our idea but our main contribution remains the high level guidance.
The main aim of the research presented here is to provide a method that would allow us to take any 3D urban model, whether representing a reconstruction of a real city or something entirely computer generated and simulate the behaviours of the inhabiting entities with no user intervention. We want the result to be fairly realistic, which for the model of a real scene, that would mean that the resulting densities of pedestrian should match to a certain degree the observed ones, but also for an imaginary model the densities should be such that would match the expectations of an expert architect.
Affordance Based Guidance of the Avatars
Our method builds on the ideas presented in the paper of Turner and Penn, where Gibson's theory of affordances is revisited. According to Gibson the agent perceives the contents of the environment and uses affordances within it to guide its actions without reference to superior representational models. He asserts that the available walkable surface affords movement. We have implemented the above idea in practice as a simple rule set that makes avatars more likely to walk in directions where they have the "larger" views. we can assume that they will change direction only at the junctions and thus only there do they need to have vision to guide their decisions. In fact we can pre-compute the visibility information at the junctions and store it with the model.
The system works in two steps. The preprocessing, which computes the visibility at the junctions as mentioned above, and the on-line guidance of the avatars.
Preprocessing the Environment
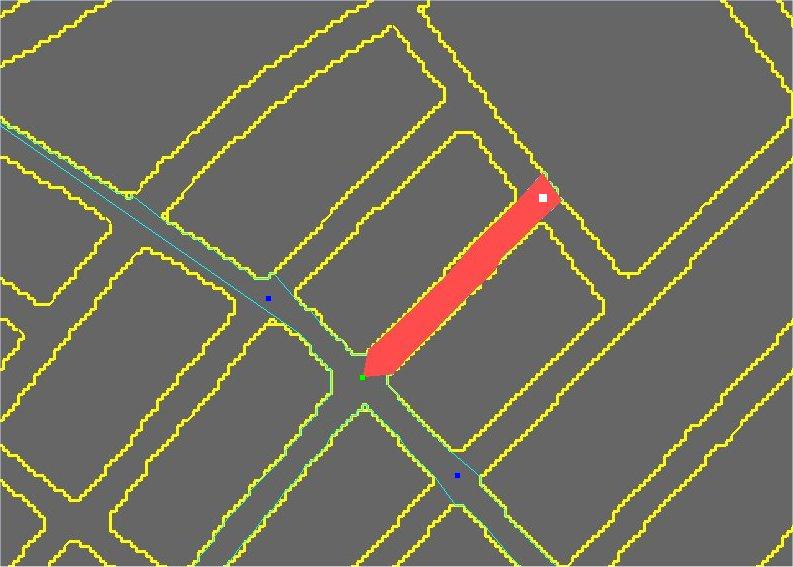
At the centre point of each junction we have to compute the available walkable surface in each direction. For this we make use of the visibility polygon (or viewshed). An example of the visibility polygon of a junction is shown in Figure 1. Once we have the viewshed we can use it to compute the visible area in the direction of each of the junctions' neighbours. We estimate the visible area by taking the part of the viewshed that lies within the view-frustum when looking towards the direction of the specific neighbour. At the end of this process, all we need to store at each junction is the percentage of walkable (or visible) area that corresponds to each direction, and the actual vector that indicates the direction.
 |
 |
|
|
Figure 1: The visibility polygon of the junction (green square) is shown with a cyan line. The blue squares are the immediate neighbour junctions |
Figure 2: Red area defines the visibility of green junction towards white junction |
On-line Avatar Guidance
For each frame, to move an avatar a step forward we need first to test for collision, both against the static environment and against the other avatars. Then, depending on whether the avatar is along a road or at a junction, we either follow the curve of the road or possibly take a decision on where to turn.
To accelerate the process we discretize the ground plane of the environment into cells which are stored into an array we call the "Guidance Map". Each cell of the Guidance Map can have the value of either "Building", "Junction", or "Road". Any cell flagged as "Building" is inaccessible and the avatars need to avoid colliding with it. "Junction" cells, are those cells that lie within a small radius of the centre of a junction. For all "Road" cells, we keep the direction of the road at that point, which is derived by the direction of its centreline at that part of the road.
While the avatars are in "Road" cells, they walk along the road and, assuming there is no collision, they adopt the direction of the respectively cell. When they come up to a "Junction" cell, they take a decision on changing their direction. This decision depends on the percentages of the visibilities computed at the preprocessing. The greater the visibility towards a neighbour, the greater the probability that the neighbour will be chosen as the next target. At this point, some kind of memory is needed. Avatars need to remember which junction they have just come from and that is not considered to be a candidate, even if it has the greatest visibility of all neighbour junctions. Once the decision is taken, and while the avatars are in "Junction" cells, they change their direction gradually, taking into account their current direction and the direction towards the start of the next road. When avatars reach the "Road" cells of the new road, they continue their journey by just following the directions stored in them, as described above.
Results
To test the method we run a set of experiments with a simple model of central Nicosia. As we see in Figure 3, the town is separated into the old part, at the top of the image, which lies within the Venetian walls and has small narrow streets, many of which come to dead ends due to the barracks dividing the town, and the new part which has a longer, wider and better connected network.
|
|
 |
|
|
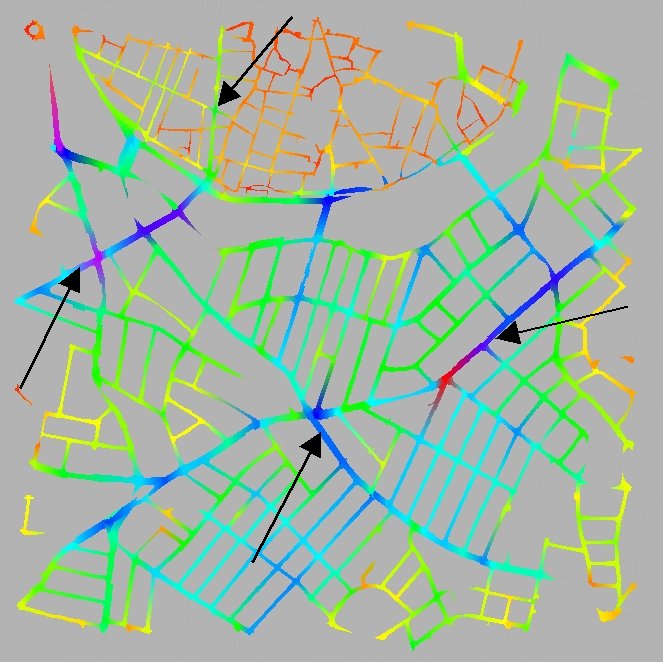
Figure 3: Initializing the avatars based on the overall viewshed size at each junction |
||
We compared the method described in the paper with one that chooses a random direction with equal likelihood for every avatar that reaches a junction. Initially, for both methods, the avatars are distributed randomly in the streets of the whole model. We let the simulation run over a certain number of frames while counting how many avatars go through each junction at every step. We use colour to show the densities at the junctions. Roads values, are shown by interpolating along junctions values at either end. Orange and yellow is used for the lower end of the scale while darker blue and red is for the higher end.
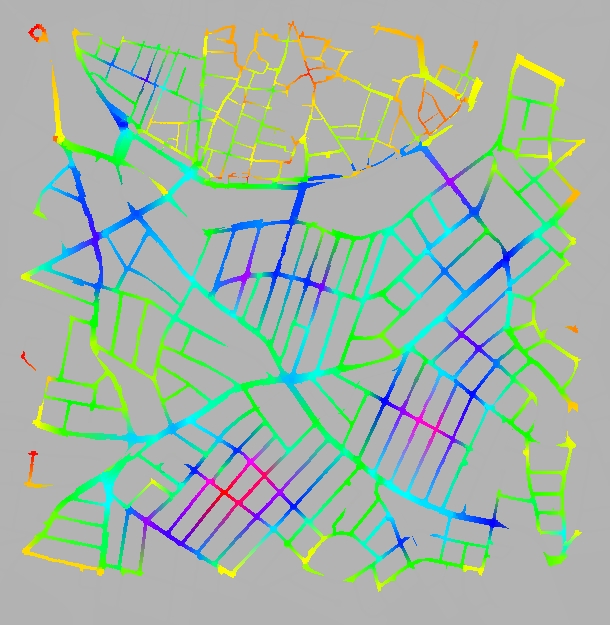
In Figure 4(a), we see the results of the random simulation after 500 frames. The affordance method looks similar at that stage since they both start from a random distribution. If we give them enough time to converge though, we begin to see the difference. The random method appears to break the town into two sectors the old and the new. The distribution within each sector come out fairly even for most roads, although there is a big difference between the two sectors. The reason for this is probably the difference in connectivity of the two parts. For the affordance method the results are much better. We can see that certain streets have a lot more density than others and these seem to match quite closely the main shopping streets of the town as it stands today. In Figure 3 we show with the black arrows the four main streets of the particular part of town.
 |
 |
 |
||
| (a) | (b) | (c) | ||
| Figure 4: Traffic counts of 10000 avatars (a) after 500 frames, (b) after 5000 frames in the random selection method and (c) after 500 frames in our method | ||||
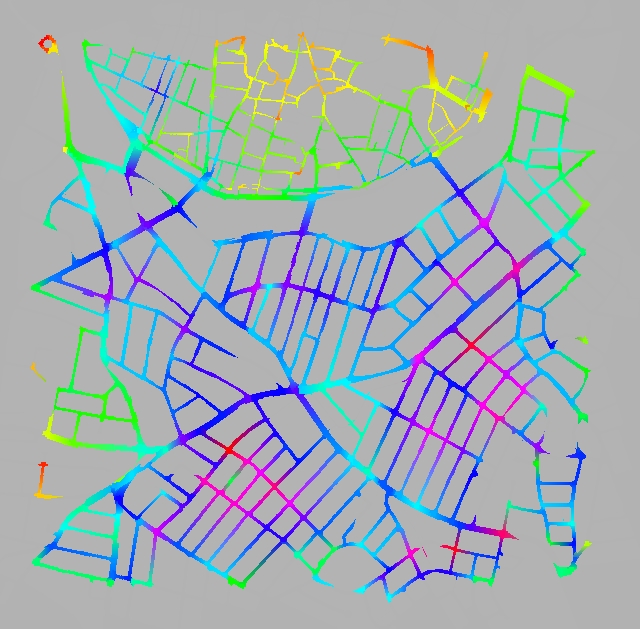
In Figure 5 we show the results of two runs of the random method with 5000 frames. In the left we employed a quarter of the avatars than we did in the right. We can see that the number of avatars does not change the results in a significant way. This is true for both methods.
 |
|
|
| (a) | (b) | |
|
Figure 5: Running the method with a different number of avatars only changes the intensity (i.e. the absolute numbers) but not the relative distribution. In this example we see the random method with (a) 2500 and (b) 10000 avatars over the same number of frames |
||
One improvement we can do is the following: instead of starting off the avatars at random positions and wait for hundreds of frames for them to converge we can compute the visibility polygon at the junctions and use the overall area of that to guide us for specifying the distributions directly from the first frame That is, near junctions with larger visibility polygon we place more avatars. We can see that actually the results of running the affordance method for 5000 frames Figure 4(c) and that of using the visibility polygon at the junctions Figure 3 are not too different.
Discussion and Conclusion
In this paper we described a new, for Computer Graphics, idea that allows us to take any urban model and populate it with minimal user intervention, as far as the high level behaviour is concerned. Although this is a very preliminary implementation we still observe realistic pedestrian movements and high speed. The method that is proposed has been implemented and tested with a complete system with 3D avatar rendering. Some screenshots of the complete 3D system are shown in Figure 6.
The method is easily extended to dynamic environments. When there is a change in the environment, for example by adding a new road or adding a road block, we can quickly update the stored information. At the point where the change has happened, we can compute the visibility polygon, and check which of the neighbouring junctions lie within it. For these ones the visibility information is no longer valid and we would need to recompute it. Everything else remains unchanged. Since we can compute a visibility polygon in a matter of a few milliseconds (<5) and a change is likely to affect only junctions in the close vicinity, we expect the whole process to run almost unnoticed by the user.
To make the results more realistic and take in account some of the other factors affecting human behaviour, the system could be extended with the addition of attractors. Pedestrians will then take their decision for the next junction not only based on visibility, but also based wether an attractor is visible from their current position. There still remains the issue of populating open spaces that have no junctions where the decisions can be taken. In such cases we intend to use a method where the visibility information is computed for every point in the 2D space and a new decision is taken every few steps. This of course has the problem that it is very difficult to prevent the avatars from taking wondering paths. A finer tuning will be required.
 |
 |
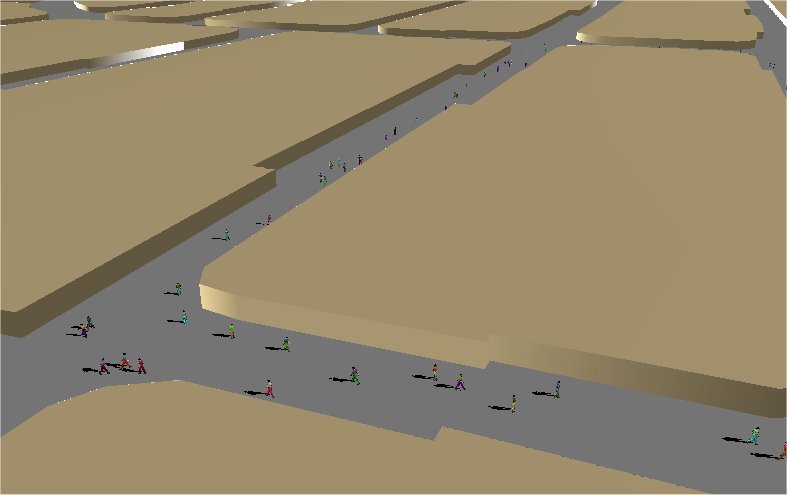 |
||
|
Figure 6: Some screenshots of the system running with the 3D avatars |
||||
You can download the complete paper "Automatic High Level Avatar Guidance Based on Affordance of Movement" in pfd format here
Check out this webpage for newer results of the project!!!